
Part 3: Technology
Welcome to the latest in our Devblog series about the making of our first Discord RPG: Torn Tales. (Check it out for yourself here: https://discord.gg/JVKjCuZ)
The previous installments of this blog talked about the design behind our RPG – now it’s time to delve into some of the technology used to build it.
Discord provide a comprehensive web API, allowing you to automate pretty much anything a human can do with the messenger client. In fact that’s the best way to think of it – your interface into Discord IS just another client, just like another person reading and responding to messages, except it’s done by a computer, or “bot”.
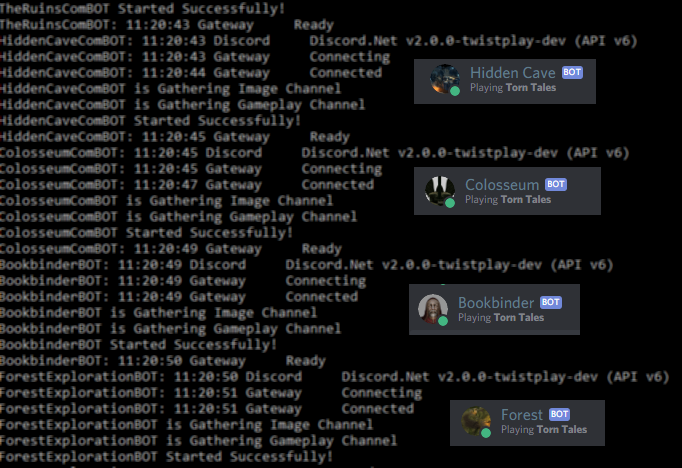
Firing up the bots…
There are a number of wrappers around their API allowing you to talk to Discord using your programming language of choice – check out some of the options here (https://discordapi.com/unofficial/comparison.html)
In our case we went with RogueException’s excellent Discord.NET library (https://github.com/RogueException/Discord.Net) – reason being we have a team of C# coders who do a lot of Unity development, so it’s a natural fit. There are of course many other popular choices out there (there’s probably thousands of bots written in Javascript or Python), but the advice we’d give is to use what you already know well, so that you can be productive quickly.
Discord.NET is available on GitHub and NuGet
C# has traditionally been built around a feature rich (large!) set of libraries known as the .NET framework. In the past few years Microsoft have been producing a much more streamlined version of the .NET framework, known as .NET Core. It can be used both for standalone executables, and for running “Kestrel” web servers using ASP.NET Core – which unlike classic ASP.NET servers are actually pretty performant. We don’t actually need ASP.NET in our case, as the server code is just a backend that talks to Discord and doesn’t need users to access directly via web calls.
Things break.
If there’s one thing you should remember about using a Discord API (either directly through web calls, or using a wrapper), it’s that any call can fail any time for any reason. If it can go wrong, it will (that’s someone’s law isn’t it? can’t remember!). The Internet is a flaky place, messages get lost, and servers have all sorts of anti-spamming methods in place. Discord’s own servers sit behind Cloudflare, which filters assorted nasties with the aim of keeping a good end-user experience where possible. They also use a rate-limiting system, which stops a single bot sending too many messages in a short space of time.
These limitations need to be coded around – if something fails, you need a retry mechanism, don’t assume your Discord library of choice is going to handle it all for you. We quite often see “500 internal server error” messages come back when updating a message or sending an image. Whilst the library does its best at retrying for typical web failures, it may give up and tell you something broke, and in fact you don’t want it sitting there forever retrying the same thing over-and-over and expecting to get different results (that’s the definition of insanity isn’t it?). Your code needs to handle it, in the way only it knows best.

Typical errors. We see these a lot!
And remember often you won’t see these issues until putting your server into the hands of real people – it might work fine in your test environment during the normal working day, but UTC 3:00am in the morning when Discord is itself under heavy load, errors will start appearing …
Next big decision is that the code needs to run somewhere, 24 hours a day – Discord bots don’t just magically exist in the cloud and are not normally hosted by Discord themselves. Something needs to actually execute the code.
We use one of Amazon’s AWS virtual servers (EC2) for this. There are many options, and we’ve tended to find that Google/Azure/Amazon don’t end up being the cheapest when you start adding in Internet metering and storage/IO costs, it can often be cheaper to use an all-inclusive style VPS pricing model. However, we went down the Amazon route in this occasion due to our database solution (read down a bit for more on that) …
Amazon’s EC2 “T2” series of machines run using burst technology – this means you get a certain baseline of performance (e.g. 20% of a CPU), but are occasionally allowed to burst to a fuller amount of CPU time. This makes sense for a lot of web applications – for medium to low use servers queries will not arrive in a nice steady stream, just like buses they will clump together. So this sort of server can often be pretty cost effective compared to paying for lots of capacity that 90% of the time just isn’t getting used.

Multiple players fighting at once
Our case is a little different though – we’re not receiving webcalls directly from players, but sending/receiving messages from the Discord API. Our game structure is such that combat occurs in rounds, with a number of things refreshing at fixed intervals. Each of our bots is effectively typing into a Discord client in its own right, and each of these connections processes a certain baseline of traffic continuously. Because of this, the very lowest T2 servers (e.g. T2.nano and T2.small) did not meet our needs and it was necessary to go for higher specs – symptoms of poor performance included bots replying back to player messages very slowly.
One great thing about .NET Core is that it can be run on a Linux machine, so no need to shell out extra money on Windows licensing for your server (and gives you many more options to shop around for virtual servers). We’re were very pleased to find that Discord.NET is completely compatible with this tech.
Being a role-playing game, the Torn Tales Discord RPG has a degree of persistence. Players have stats,and can leave the game and come back whenever they want, days or weeks later. The game code is continually updated, and the server needs to be rebooted sometimes. So all that data needs to be stored somewhere safely in a way that can be read/written quickly – it can’t just stay in the computer’s memory. We needed a database.
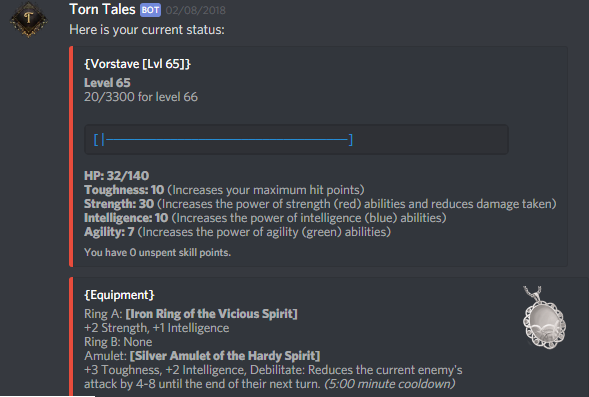
A player’s stats in the Torn Tales Discord RPG
There’s a smorgasbord of options for this, but without delving too much into the pros and cons of each database flavour, we opted for a “NoSQL” solution, like many modern servers. Often older databases use a relational model, meaning the tables of data cross-reference each other, allowing complex queries to be built up using languages like SQL (Structured Query Language). Unfortunately this model doesn’t always scale in a desirable way to how the modern web is used, particularly when faced with millions of transactions in different places around the world. NoSQL solutions lose the flexibility of these complex queries, but do allow large volumes of data to be distributed to different locations efficiently.
Our particular choice here was Amazon DynamoDB (https://aws.amazon.com/dynamodb/). It scales and backs up automatically, and takes out a lot of hassle of having to manage a database. And there’s an API for talking to the database directly from C#/.NET.

Some data from the Item table
Their pricing model is interesting- rather than size of the database, it’s charged on throughput, in other words how often you are reading and writing data to tables. Below a certain threshold, using the database is free, obviously a compelling price point! This free tier does require careful design of both the number of tables and how often each table will be accessed (which Amazon provide fine grained controls for). For many applications keeping within the free tier is definitely achievable, but if you need more it’s setup to automatically scale to your requirements.
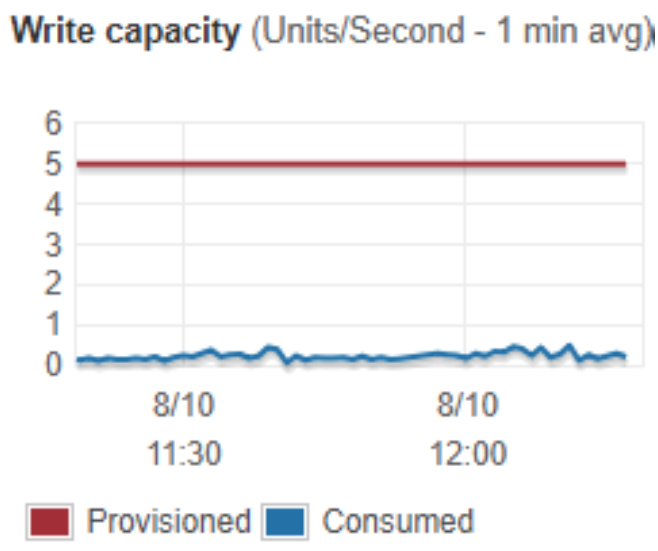
AWS DynamoDB Metrics for monitoring writes
Amazon currently allow 25 reads and 25 writes per second (combined across all tables) for free. This is actually an average across a few minutes, so you can “burst” queries at a higher rate for a short space of time – for example when a server is starting up. 25 doesn’t sound a lot, but combined with memory caching it’s plenty for our RPG – imagine 25 players all needing to write their HP back to the database in the space of 1 second, that’s a pretty intense fight. And even if one player has to wait a few seconds before their HP is persisted the database, they’ll never know, as the most up-to-date value is cached in memory anyway
Some enemy data from the database
What does need careful attention are “scans” – i.e. things that read the whole table, as this can count as many read operations at once. Remembering it is not a relational database, you have to think carefully about your access to the database, just querying an arbitrary field in your table can requiring reading the whole thing back. For example if we wanted to query all players who are dead (HP 0) – by defaultwe’d have to read (scan) the whole table in, and check the HP field row by row. Aside from being inefficient it can actually cost you money. The solution to this is to add a secondary index (a sort of special table of the HP values tying back to the player table). These are straightforward to create and automatically update themselves, but do remember writing to the index also counts against your quota of throughput.
We chose to keep our database and virtual server in the same location (in our case Amazon’s Paris datacenter), which has provided excellent performance and avoided the need for Internet charges sending database traffic to the outside world.
So there we have it – an AWS Linux server with .NET Core/C# code running the game logic, sending messages through the Discord API, and querying our DynamoDB database for player information. There’s no one right way to do it, but this combination of technology fitted our needs.

High level system diagram
Thanks for reading folks! Next time this blog is going to talk about promoting the server to get new players in. And remember you can join our Discord totally for free here: https://discord.gg/JVKjCuZ
<< Go To Part 1
<< Go To Part 2
Go To Part 4 >>




